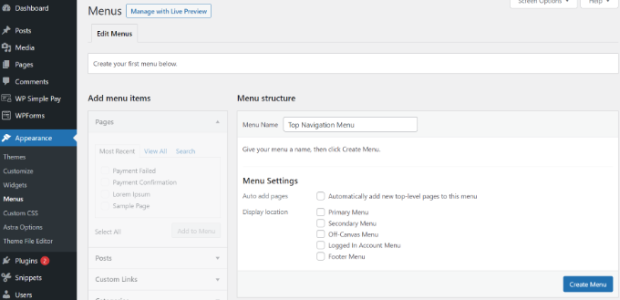
如何在WordPress中添加导航菜单(初学者指南)
您想为您的WordPress网站添加导航菜单吗? WordPress带有拖放菜单界面,您可以… 继续阅读 如何在WordPress中添加导航菜单(初学者指南)
- 发表于:
-
作者:
Hao Chen
- 分类: PHP, WordPress, WordPress入门教程
- 标签: add, Guide, Menu, Navigation, WordPress, 添加导航菜单
技术教程与经验分享站点
您想为您的WordPress网站添加导航菜单吗? WordPress带有拖放菜单界面,您可以… 继续阅读 如何在WordPress中添加导航菜单(初学者指南)
解析文档子节中的相关值时,创建嵌套加载器会很有用。想象一下,您从页面的页脚中提取详细信息,如… 继续阅读 爬虫蜘蛛项目加载器Item Loader类详解之嵌套加载器详解 (22)python SCRAPY最新教程1.51以上版本
classscrapy.loader.ItemLoader([item,selector,r… 继续阅读 爬虫蜘蛛项目加载器Item Loader类详解之ItemLoader对象详解 (21)python SCRAPY最新教程1.51以上版本
Item Loader包含一个输入处理器和一个输出处理器,用于每个(item)字段。输入处理… 继续阅读 爬虫蜘蛛项目加载器Item Loader类详解之输入输出处理器 (19)python SCRAPY最新教程1.51以上版本
项目加载程序提供了一种方便的机制来填充已删除的项目。尽管可以使用他们自己的类字典API来填充… 继续阅读 爬虫蜘蛛项目加载器Item Loader类详解之使用项目加载器填充项目 (18)python SCRAPY最新教程1.51以上版本
optparse– 用于命令行选项的解析器 源代码: Lib / optpars… 继续阅读 optparse用于命令行选项的解析器 – Superseded Modules(Python教程)(参考资料)
pty– 伪终端实用程序 源代码: Lib / pty.py pty模块定义了处… 继续阅读 pty伪终端实用程序 – Unix特定服务(Python教程)(参考资料)
formatter– 通用输出格式化 自版本3.4以后不推荐使用:由于缺少使用,… 继续阅读 formatter- 通用输出格式 – 其他服务(Python教程)(参考资料)
email:示例 以下是一些如何使用email包来读取,写入和发送简单电子邮件以及更复杂的M… 继续阅读 :示例 – – 电子邮件和MIME处理包(Python教程)(参考资料)
平台支持 asyncio模块设计为可移植的,但是某些平台在平台的底层架构和功能方面存在细微差… 继续阅读 平台支持 – 异步I / O(Python教程)(参考资料)