如何在WordPress中添加Cookie弹出窗口
您想在WordPress中添加cookie同意弹出窗口吗?您的WordPress网站可能会在… 继续阅读 如何在WordPress中添加Cookie弹出窗口
- 发表于:
-
作者:
Hao Chen
- 分类: PHP, WordPress, WordPress插件
- 标签: cookie, Cookie弹出窗口, WordPress, WordPress GDPR插件, 添加Cookie弹出窗口
技术教程与经验分享站点
您想在WordPress中添加cookie同意弹出窗口吗?您的WordPress网站可能会在… 继续阅读 如何在WordPress中添加Cookie弹出窗口
此页面描述了Scrapy附带的所有下载中间件组件。有关如何使用它们以及如何编写自己的下载程序… 继续阅读 爬虫蜘蛛Scrapy内置下载中间件详细分析DOWNLOADER_MIDDLEWARES(58)python Scrapy教程1.51以上版本
有时,对于大型网站,最好暂停抓取并稍后恢复。 Scrapy通过提供以下设施支持此功能: 一个… 继续阅读 爬虫蜘蛛管理暂停和恢复抓取(54)python Scrapy教程1.51以上版本
以下列出了使用Firefox进行抓取的提示和建议,以及一系列有用的Firefox附加组件,以… 继续阅读 Scrapy使用Firefox进行抓取(47)python Scrapy教程1.51以上版本
Scrapy与BeautifulSoup或lxml相比如何? BeautifulSoup和l… 继续阅读 爬虫蜘蛛常见问题解答(42)python Scrapy教程1.51以上版本
http.cookiejar– HTTP客户端的Cookie处理 源代码: Li… 继续阅读 – HTTP客户端的Cookie处理 – Internet协议和支持(Python教程)(参考资料)
http.cookies– HTTP状态管理 源代码: Lib / http /… 继续阅读 – HTTP状态管理 – Internet协议和支持(Python教程)(参考资料)
关于WordPress登录界面最烦人的部分是当你忘记勾选“记住我”复选框并点击登录时。现在,… 继续阅读 如何让WordPress永远记住我忘记你
我们向您展示了如何让WordPress永远不会忘记你。这允许您保持登录到WordPress站… 继续阅读 如何从WordPress登录中删除记住我选项
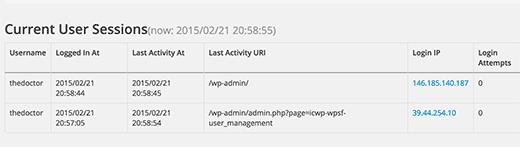
默认情况下,WordPress用户可以同时从多个位置登录帐户。这可能会损害您的多作者Word… 继续阅读 如何阻止用户在WordPress中共享密码